
A few months ago I published an essay arguing that llms.txt is an elegant solution to a problem nobody important is willing to solve. No major AI platform reads it. Not OpenAI, not Google, not Anthropic, not Meta. The standard, I wrote, “sits unused, waiting for a problem that the powerful have chosen not to solve.”
Then I went back to my portfolio and built more of it.
I added an agent card. I added an A2A endpoint that agents can actually POST to. I wrote markdown twins of every page on the site. And I added a manifest of skills an agent is told to verify, not just trust, before acting on them. If you only read the first essay, this looks like a man losing an argument with himself.
It is not. There is one distinction that makes building all of this the opposite of insane.
Discovery is dead; usability is the live question
The thing I declared dead was discovery. The idea that publishing the right file would make an AI crawler find me, rank me, surface me. That bet has not paid off and there is no sign it will. In my follow-up on AI slop I went further and reframed the entire category: these standards are valuable “not as a way to be discovered, but as a way to be verified once a user has found you.”
Hold onto that sentence. It is the hinge of this whole post.
Because there is a completely different scenario the discovery debate ignores. A human is sitting in front of an agent (Claude, ChatGPT, some autonomous research thing) and they say: go look at Cameron’s site and tell me what he’s done with MCP. The agent is already here. Nobody had to discover me. The question is no longer “will it find me.” The question is:
When it gets here, can it actually do anything?
That is a usability question, not an SEO question. And usability for an agent has a spectrum:
- Can it read me? Most sites hand an agent a tag-soup DOM full of nav chrome, cookie banners, and analytics noise, then make it guess which
<div>is the article. - Can it understand me? Even with clean text, can it tell a blog post from a project, find the publish date, know which pages are drafts?
- Can it act on me? If the human says subscribe me to his newsletter or send him a message, is there a door the agent can open, or does it have to scrape a form and forge a POST?
My RAG chatbot, Ask, already handles the conversational half of this. This post is about the other half: the static, declarative, machine-addressable surface underneath. The part an agent reaches for when there is no chat box, just a URL and an intent.
I built it in five layers. None of them is a traffic play. Every one of them is a usability or verification mechanism for the agent a visitor already brought with them.
Every page has a markdown twin
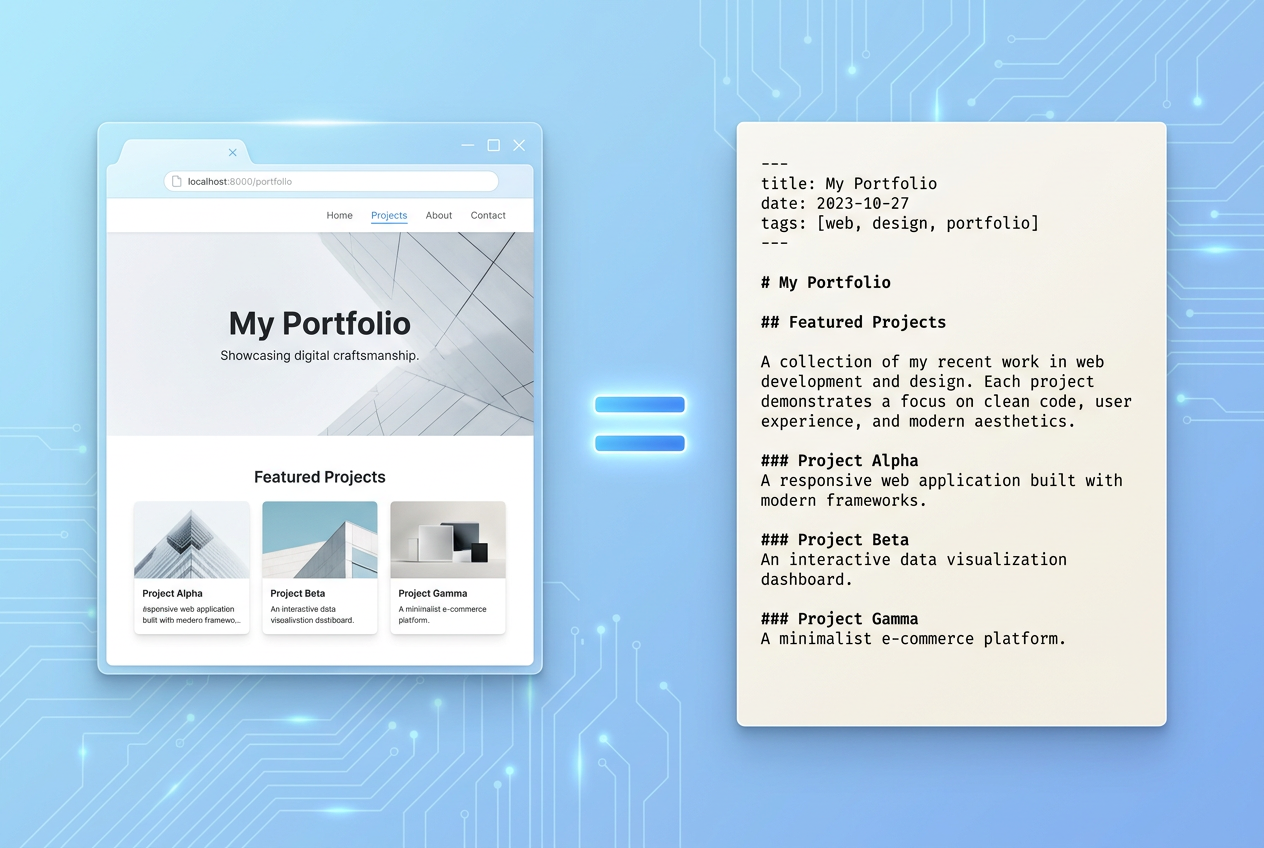
Start with reading, because if an agent cannot cleanly read the page, nothing above it matters.
Every blog post on rye.dev is served at /blog/<slug>.md, and every project at /projects/<slug>.md. These are real routes: Astro file routes at src/pages/blog/[...slug].md.ts and src/pages/projects/[...slug].md.ts, with prerender = true so they bake to static files at build time.
Here is the part I care about: these do not convert HTML to markdown. They reconstruct it. The route takes the source content and emits a fresh YAML frontmatter block (title, description, date, updated, tags, author, plus a canonical_url I inject) followed by the raw markdown body, served as text/markdown; charset=utf-8. No nav, no footer, no cookie banner. Just the document, the way I actually wrote it.
Each response also carries a non-standard header I made up because I wanted it: x-markdown-tokens, set to ceil(markdown.length / 4). That four-chars-per-token estimate lets an agent budget its context window before it spends a fetch. A small courtesy, but the whole exercise is courtesies.
There is a second way in, for agents that don’t know about the .md convention: HTTP content negotiation. Request the canonical HTML URL (/blog/foo, or /about) with Accept: text/markdown, and middleware serves you markdown instead. For blog and project pages it internally rewrites to the prebuilt .md sibling. For the eight static pages (/, /about, /now, /uses, /colophon, /reading, /resume, /blogroll) it serves hand-authored markdown twins embedded in the Worker bundle: src/data/static-page-md/*.md, imported via Vite’s ?raw. One resource, two representations, picked by a header. Content negotiation working exactly as specified.
The part that took the longest was the part you can’t see
I want to be honest about how much fighting the platform this took, because the clean result hides it.
Runtime HTML-to-markdown is impossible here. The obvious move (let a request come in, grab the rendered HTML, run it through turndown or cheerio) does not work on Cloudflare Workers. Those libraries pull in parse5, which is Node-only, and they crash the Workers runtime at module load. Not at call time. At import. So the conversion can never happen at the edge. It has to happen at build, which is why these are reconstructed routes, not a clever middleware filter.
run_worker_first is a trap. Cloudflare lets you ask the Worker to run before static assets are served. Except for routes that match a prerendered asset, serve_directly silently overrides it and the asset is handed back before your code runs. _routes.json does nothing: that is a Pages mechanism, and this is a Workers deploy. And Cloudflare’s own zone-level “Markdown for Agents” feature, which would replace this entire layer, requires a paid plan. rye.dev is on the Free plan. So I built the free version by hand.
There’s one subtlety that cost me an afternoon. The static .md routes must be prerender = false and there must be a registered SSR route at src/pages/[slug].md.ts, or Workers Static Assets answers the request first and 404s it before middleware ever runs. The Worker has to be the thing that picks up the phone.
One more, because it bit me in production: Vary: Accept is the correct header to set, and I set it. But Cloudflare’s edge cache does not vary on Accept. So without intervention, the edge could cache an HTML body and then hand it to an Accept: text/markdown request. The fix is to force Cache-Control: private, no-store on the negotiable static-page paths. You give up edge caching on a handful of routes to guarantee correctness. Worth it.
The index nobody reads, built anyway, honestly
On top of the twins sits the file I already eulogized.
public/llms.txt is hand-authored. I’ll say that plainly, because the next file isn’t, and the distinction matters. It follows the llmstxt.org structure: an H1, a blockquote summary, then ## About, Featured Projects, All Projects, a reverse-chronological Technical Blog with dates, Technical Expertise, Connect, and Optional. It documents the .md-appended convention right at the top so an agent reading it knows the twins exist.
Being hand-authored, it can drift. So next to it is public/llms-full.txt, which is generated by scripts/generate-llms-full.ts as the first step of every build. It inlines the full body of every non-draft post and project (currently around 25 posts and 15 projects) into one grep-able file. If an agent has no fancier tool, the instruction is blunt: fetch llms-full.txt and grep it.
Do I think OpenAI is fetching this file? No. I said in the first essay that nobody is, and I stand by it. But it is trivial to generate when you already write everything in markdown, it signals to a human inspecting the site that I take the machine-reading problem seriously, and it gives my own tooling something clean to read. The cost of building it was an afternoon. The cost of being wrong about adoption is zero, because I lose nothing by being early. That was the entire argument for building llms.txt anyway, and it is the entire argument here.

An agent card that tells the truth about itself
Now we move from “read me” to “here is my interface.”
At /.well-known/agent-card.json lives a static, hand-authored A2A Protocol AgentCard, version 1.0.0. It names the provider (https://rye.dev, “Cameron Rye”), points documentationUrl at the agent-skills index, and uses the site favicon as its icon. Its supportedInterfaces is a single entry: { url: https://rye.dev/a2a, protocolBinding: JSONRPC, protocolVersion: 1.0 }. That /a2a URL is the door. We’ll walk through it in the last layer.
The honest part is capabilities:
"capabilities": { "streaming": false, "pushNotifications": false, "extendedAgentCard": false }All false. No streaming, no push, no extended card. I could have left those out or fudged them aspirationally. I set them false because they are false, and an agent that reads streaming: false and then doesn’t wait around for an event stream is an agent I’ve saved a timeout.
The card advertises five skills: search-blog, get-post, subscribe-newsletter, submit-contact, and mcp. Four of those are callable over the live endpoint. The fifth, mcp, is not an executable skill. It is a pointer that says “there is an MCP server at https://rye.dev/mcp, go talk to it.” I list it as a skill because the A2A card is the most likely place an agent already on the site looks first, and I’d rather hand off cleanly than leave the MCP server undiscovered. But I’m telling you here what the card can’t: four do something, one points elsewhere.
The dotfile problem, which I will mention exactly once per file
Cloudflare Workers Static Assets will not serve any file under a literal .well-known/ directory. The dotfile prefix is filtered out of the asset bundle. So nothing I just described could physically live where its URL says it lives.
The workaround, which recurs across this entire surface: every well-known file lives under public/wellknown/ (no dot) and is exposed at /.well-known/ via a status-200 internal rewrite in public/_redirects. The URL bar stays /.well-known/agent-card.json; the bytes come from wellknown/. public/_headers then layers on the CORS, Content-Type, and cache headers. (For the namespace background on why .well-known/ is the right place for any of this, I wrote a whole post on well-known URIs.)
And because a card that lies about its skills is worse than no card, there’s a drift-guard test (tests/a2a-agent-card.test.ts) that asserts the card’s skill descriptions match the agent-skills index verbatim. The two cannot silently diverge.

Skills an agent is told to verify before trusting
public/wellknown/agent-skills/index.json is the verification manifest: a pointer set for an agent already on the site, declaring $schema https://schemas.agentskills.io/discovery/0.2.0/schema.json. It’s a flat skills array. Each entry has a name, a type of "skill-md", a description, an absolute url to a SKILL.md, and the interesting one: a digest of the form sha256:<hex> computed over that SKILL.md’s bytes.
Each skill is a SKILL.md file: YAML frontmatter (name, description) plus a freeform markdown body of instructions written for an agent to read and follow.
The digest is the whole point, and it’s the theme of this post wearing a hat. The discovery schema (v0.2.0) carries a per-skill sha256 digest precisely so a client can verify the artifact bytes before trusting a skill. scripts/agent-skills-digest.mjs (pnpm agent-skills:digest) recomputes them; edit a SKILL.md and forget to re-run it, and you ship a stale digest that a compliant agent will reject. That is not a bug. That is the verification handshake doing its job, the same thing I said standards are actually good for. Not “trust me because I’m in the index,” but “here’s the hash, check it yourself.”
The five skills split into three kinds.
Read skills. search-blog tells the agent to prefer the MCP search_posts tool, fall back to fetching llms-full.txt and grepping, then read a hit via MCP get_post or GET /blog/<slug>.md. get-post describes get_post { slug } → { slug, frontmatter, body, url }, or the plain GET /blog/<slug>.md with Accept: text/markdown, drafts excluded, response carrying that x-markdown-tokens header. Reads are cheap and safe.
Write skills, where it gets interesting. subscribe-newsletter is POST /api/newsletter with { email, source }, double opt-in, returning 200 / 400 / 429. submit-contact is POST /api/contact with { name, email, subject, message } under field-length constraints. Both are rate limited and both are same-origin enforced: the Origin must be https://rye.dev.
That same-origin rule creates a fork in the road, and the skills document both branches honestly:
- An in-browser agent (something running as a page-side tool) inherits the page’s Origin, so it uses the WebMCP
subscribe_newsletter/submit_contacttools and sails through the check. - An out-of-browser agent can’t forge a same-origin request and shouldn’t try, so the skill tells it to do the polite thing: send the human to
https://rye.dev/#newsletteror the contact form. The agent doesn’t pretend to be the user. It hands the user back the wheel.
The mcp pointer. The fifth skill-md entry, mcp, has its own SKILL.md and its own digest, but it isn’t callable over /a2a. It describes connecting to the MCP server at https://rye.dev/mcp, Streamable HTTP, stateless (no Mcp-Session-Id), protocolVersion 2025-06-18, six read-only tools: list_posts, search_posts, get_post, list_projects, get_project, get_about. Which brings us to the layer where things actually execute.
The endpoints that do something
Everything above is description. /a2a is action.
It is live, not a placeholder: a server-rendered Astro route at src/pages/a2a.ts, prerender = false, speaking JSON-RPC 2.0, stateless and synchronous. It supports exactly one method, message/send; anything else gets a clean JSON-RPC -32601. It never returns an A2A Task: no streaming, no async job queue, which is precisely what the card’s all-false capabilities promised.
Dispatch works like this. The client sends a message whose parts include a DataPart:
{ "kind": "data", "data": { "skill_id": "get-post", "args": { "slug": "ai-slop-is-a-search-problem-now" } } }Four skills are callable through it: search-blog, get-post, subscribe-newsletter, submit-contact. Send a text-only message with no DataPart and you get a help reply listing exactly those four. No guessing.
Code reuse is the entire architecture, not a detail. The read skills call the same searchPosts / getPostBySlug functions the MCP server uses. The write skills call the same action handlers as the /api/newsletter and /api/contact REST routes, which means they inherit the existing validation and rate limiting for free: newsletter 3/hour, contact 5/hour, both fail-closed, keyed by client IP. I did not build a parallel A2A backend. I put a JSON-RPC face on the logic that already existed. One source of truth, three front doors (REST, MCP, A2A).
Being candid about the security posture
/a2a is deliberately unauthenticated, with open CORS: Access-Control-Allow-Origin: *. I want to be straight about that rather than let you discover it.
The reason is structural. My same-origin CSRF check is scoped to the /api/ prefix, and /a2a lives outside it so that a third-party agent (which by definition can’t present my Origin) isn’t blocked at the door. Put it under /api/ and the CSRF guard would reject every legitimate external agent, which defeats the entire point of being reachable by agents a human sent.
The honest tradeoff: anyone can POST to /a2a. It is an open endpoint. What protects me is not the transport but the fact that the only write paths reuse the rate-limited, fail-closed handlers above. The read paths expose only already-public blog content, so they are intentionally not rate-limited. An open read endpoint over my own published writing is not a thing I need to defend. An open write endpoint would be, which is why the writes keep their limits no matter which door they came through. That’s hardening by design, not an oversight. I’m telling you it’s open because the design expects it to be open.
The sibling is /mcp (src/pages/mcp.ts), with its own server card at /.well-known/mcp/server-card.json: serverInfo.name "rye.dev", title “Cameron Rye Portfolio MCP Server”, streamable-http transport, capabilities ["tools"], the six read-only tools. The MCP card and the agent-skills index point at each other, so an agent that lands on either one finds the other.
The table of contents that holds it together
Five layers is a lot of surface. So there’s a top-level map.
/.well-known/api-catalog is an RFC 9727 linkset, the table of contents for an agent that’s already here. It links service-desc → /openapi.json, service-doc → /llms-full.txt, status → /api/health, the MCP server → /mcp, and the agent-skills index. It does not list the OAuth or web-bot-auth files. Those are placeholders, and a catalog that advertised them would be lying. (More on that in a second.)
Reinforcing the catalog, an RFC 8288 Link header rides on responses (emitted statically in _headers and dynamically on SSR responses in middleware) pointing at the rels for llmstxt.org, agentskills.io, modelcontextprotocol.io, and a2a-protocol.org. An agent that does nothing but read response headers still gets pointed at every entry point.
And for the humans: the homepage has a “Built for humans and AI agents” section (driven by src/data/agent-endpoints.ts) that just lists these endpoints in plain sight. I’m not hiding the machine surface in the metadata. I’m proud of it.
The whole thing is kept honest by drift guards I’ve already mentioned in passing: the card-versus-skills verbatim test, the digest recompute script, and build-time hash checks. The failure mode I’m most afraid of is not “no agent uses this.” It’s “an agent uses this and I’ve quietly lied to it.” The guards exist so I can’t.
So does anything actually consume this yet?
Honest answer: mostly nothing.
No major platform is fetching my llms.txt or my agent card on its own. I said that months ago and nothing has changed. The thing that does consume this surface is my own tooling (Ask reads the clean content, my MCP and A2A endpoints reuse it) plus whatever agent a visitor decides to point at the site today. That’s it. That’s the honest scorecard.
And it reconciles perfectly with what I argued before, because I never promised this would bring traffic. It won’t. This is not a discovery play; I retired that idea in print. These are the exact benefits I pre-committed to in the llms.txt piece, and they still hold: it’s trivial to generate when you already write in markdown; it signals technical care to anyone who looks; it lets me experiment with these protocols before they matter; it prepares me for if adoption ever comes; and (the one I underrated) the markdown twins double as genuinely clean documentation of my own site. The work pays for itself the day I build it, regardless of who shows up.
The reframe from the slop essay holds all the way down. These standards are not how an agent finds me. They’re how an agent that a human already pointed here can read me cleanly, understand my structure, verify what it’s about to trust, and act through a door I deliberately left open. Usability and verification. Not SEO.
Which leaves exactly one question unanswered, and it’s the good one.
Everything here answers what can an agent read and do on this site. It says nothing about who is this agent, and should I trust it. My /a2a endpoint is open; right now it has no idea whether the thing POSTing to it is a research assistant or a scraper wearing a trench coat. There are already placeholders sitting in /.well-known/ for the answer: an http-message-signatures-directory publishing an Ed25519 public key for Web Bot Auth, and OAuth discovery metadata under RFC 8414 / RFC 9728. I’ll be blunt about their status, because it’s the same honesty the digests demand: the key is published but no request signing is implemented, and there is no OAuth server behind that metadata. The site cannot authenticate a bot or run an OAuth flow today. The doors are framed; the locks aren’t installed.
Installing the locks (agent identity and verification) is the next post.
For now I’ve built an interface, told the truth about every corner of it, and left it open for the agents a human brings. That was always the realistic goal. Not to be discovered.
To be usable once you arrive.
Companion essays:
- The /llms.txt Standard: An Elegant Solution Nobody’s Using. The prequel: why no major platform reads these files, and why I built them anyway.
- AI Slop Is a Search Problem Now. The reframe this whole post stands on: standards as a way to be verified, not discovered.
- Standardizing Web Metadata with Well-Known URIs. The
.well-known/namespace background behind the agent card and api-catalog. - Building Ask: A RAG-Powered Portfolio Chatbot. The conversational counterpart to this static, declarative surface.
Keep Reading
Building Clarissa: Learning How AI Agents Actually Work
I built a terminal AI agent from scratch to see how they really work: the ReAct loop, safe tool execution, and what context management actually takes.
ActivityPub MCP Server: Bridging AI and the Fediverse
How I taught Claude to explore the Fediverse: an MCP server that discovers actors, fetches timelines, and queries Mastodon-compatible instances.
Building a Gopher MCP Server: Bringing 1991's Internet to Modern AI
Why I wired a 1991 protocol into modern AI: gopher-mcp gives assistants the small internet's text-first content with almost no protocol overhead.
Subscribe
Was this helpful?
Discuss
Ask can help explain concepts, provide context, or point you to related content.